Last time we discussed the basics of linear motion. In this post, we’ll talk about the basics of assigning shapes and detecting collisions between these shapes. But before we do that, a quick aside:
It took me longer to get to this post than I had intended, and unfortunately I worry this will be the trend due to the various demands on my schedule. Therefore, reluctantly, I’m going to keep the posts more brief and in overview form so that I can produce them quicker to get the main points across. If you want a more thorough explanation of some specific portion, please let me know in the comments and I can spend time on just those parts to flesh them out more. This way, I can still get content out there quicker, but also address technical depth on-demand where it’s actually needed.
With that out of the way, let’s get back to shapes. We want to assign each object a shape, and these shapes will assume the world transform of the parent object they are a part of. For instance, if I define a circle around an object as it’s shape then move the object, I expect the circle to follow that movement as well, so that it’s consistently enclosing the object I assigned it to. Instead of duplicating the transform info to the shape, we just pass it along with the shape when desired. This keeps the shape type as simple as possible, just representing the shape in the local space of the object.
We can have different kinds of shapes, so each shape gets a Type member, letting us know what type of shape it is. We’ll start off with 2 types of shapes: circles and boxes. A circle is an appropriate shape to use for something that’s roughly the same dimensions in both horizontally and vertically, and also doesn’t change shape much under rotation. A ball is an obvious example. Boxes can be used to cover any rectangular shapes which are longer in one direction than the other, or that need to keep rigid shape as they rotate. There are many more shapes we can define to give better representations of objects, but we’ll start with these two simple ones for now. Later, when we move to a different kind of collision detection scheme (GJK), it will become trivial to add new shapes.
A circle consists of a center point and radius. If we assume that it is always located at the position of the parent object, then the radius is all we need. There are certainly interesting scenarios where the position of the object may not be it’s center of mass, and then you would want to specify the center point of the circle as a relative position offset from the parent object, but we’ll simplify in our engine to say the two must be the same.
There are several ways we can specify a box shape. We can store a min and max point, or we can store a center and two extents. We’ll opt for the latter in our code, and use the same simplification as the circle in that the center is always the position of the parent object.
Okay, so now we have some shapes, and we’ve assigned them to the objects. Now what? As the objects move around, we’ll want to detect collisions between the various shapes and determine how we should resolve those collisions. For this, we need to define something called contact info. For any given contact between two objects, at a minimum, we’ll need a representative contact point in world space (or in the relative space of the two objects, or both), a contact normal vector representing the normal on the surface of one object where the other collided into it, and finally a penetration depth of how far the two shapes are overlapping along that normal direction. There are many other parameters we could find for more advanced resolution of the contacts, but for now we’ll stick with these.
To detect a collision and determine the contact info, we define a function called Collide, which takes in 2 RigidBody objects and a ContactInfo object for output. The function returns a Boolean to let us know if there was a collision or not, and if there was, the ContactInfo parameter we passed in is filled with the result. The reason the function takes in the RigidBody type and not the shapes directly is that the RigidBody has a pointer to the shape, but also contains the position and orientation data for the object, which we’ll need to know where in the world (and at what orientation) the shape is. This function acts as a dispatcher for the actual collision detection, since we’ll currently be providing a different function to detect collisions between each combination of shape types. So, we have a Circle/Circle function, a Box/Box function, and a Circle/Box function currently.
For each pair of potentially interacting objects, we keep a data structure called the RigidBodyPair. The purpose of this structure is to hold data about the interaction of 2 bodies, including the collision data if it exists. Ideally, we’d only produce one of these pair objects when 2 bodies are in close proximity to each other (since otherwise, there’s no way they could interact), but for simplicity the current implementation just creates one for all possible pair of objects, an N^2 setup.
Let’s look at each of the collision functions in the code now, and go over the premise of each of the collision functions and how they work.
We’ll start with the simplest, the Circle/Circle test. If you imagine drawing a line from the center of one circle to the center of another, that is the closest possible distance between the two, and is the line along which a contact of the two circles must occur on if there is one. Since the distance to the surface of the circle along any line (including this one) is equal to it’s radius in that direction, that means that if the two circles were just touching along this line, then the total distance between their centers would be equal to the sum of their radii. If the two objects were intersecting, then the sum of their radii would be greater than the distance between their centers, and if they are not touching along that line then the sum of the radii would be less than the distance. Given that info, let’s take a look at the function:
bool CollideCircleCircle(RigidBody* body1, RigidBody* body2, ContactInfo& contact)
{
const CircleShape* shape1 = (const CircleShape*)body1->GetShape();
const CircleShape* shape2 = (const CircleShape*)body2->GetShape();
float r = shape1->Radius() + shape2->Radius();
float r2 = r * r;
Vector2 toBody1 = body1->Position() - body2->Position();
float d2 = toBody1.LengthSq();
if (d2 < r2)
{
contact.distance = sqrtf(d2) - r;
contact.normal = toBody1.Normalized();
contact.worldPosition = body1->Position() - contact.normal * shape1->Radius();
return true;
}
return false;
}
Next, let’s consider the Box/Circle case. The idea here is to simply and do the check in the local space of the body containing the box. This makes a lot of the math simpler. To do that, we just take the box’s world transform (which describes going from it’s local space to world) and apply it’s inverse to the circle’s world space position & orientation to transform it to the local space of the box. We exploit a few things to simplify this: 1) a circle has no meaningful orientation, so we only need to transform it’s position, 2) since we know our transform is a rotation followed by a translation, we can just do the inverses of each of these in the reverse order (instead of computing a full inverse matrix), and 3) since the rotation matrix for the box is a pure rotation, it’s inverse is equal to it’s transpose, so we can again avoid a full inverse. Putting it all together, we first subtract the box’s position from the circle’s (inverse of the translation), then we multiply by the transpose of the box’s rotation (which is the inverse). This combination has us transformed back into the local space of the box, and we can proceed with the collision check.
So, how do we actually check for the collision? There are two cases to consider: The center of the circle is outside of the box, or the center of the circle is inside the box. If it’s outside, we find the closest point on the box’s surface to the center of the circle. If the distance between that point and the center of the circle is less than or equal to the radius of the circle, it’s a collision and that’s our contact point (and the side of the box that the point is on provides the normal). If the center of the circle is inside the box (obviously we know it’s a collision then for sure), then we need to find what side of the box it’s closest to, and try to push out that way using that side’s normal as the contact normal.
bool CollideCircleBox(RigidBody* body1, RigidBody* body2, ContactInfo& contact)
{
const CircleShape* shape1 = (const CircleShape*)body1->GetShape();
const BoxShape* shape2 = (const BoxShape*)body2->GetShape();
// Transform the circle to local space of the box (box then becomes aabb)
Matrix2 rotB = Matrix2(body2->Rotation());
Matrix2 invRotB = rotB.Transposed();
Vector2 toCircle = body1->Position() - body2->Position();
Vector2 localToCircle = invRotB * toCircle;
Vector2 halfWidths = 0.5f * shape2->Size();
// If the center of the sphere is outside of the aabb
if (localToCircle.x < -halfWidths.x || localToCircle.x > halfWidths.x ||
localToCircle.y < -halfWidths.y || localToCircle.y > halfWidths.y)
{
// Find closest point on box to the center of the circle.
Vector2 closestPt = Vector2(
localToCircle.x >= 0 ? min(halfWidths.x, localToCircle.x) : max(-halfWidths.x, localToCircle.x),
localToCircle.y >= 0 ? min(halfWidths.y, localToCircle.y) : max(-halfWidths.y, localToCircle.y));
Vector2 toClosest = closestPt - localToCircle;
float d2 = toClosest.LengthSq();
float r2 = shape1->Radius() * shape1->Radius();
if (d2 > r2)
{
return false;
}
contact.distance = sqrtf(d2) - shape1->Radius();
contact.normal = -(rotB * toClosest).Normalized();
contact.worldPosition = body1->Position() - contact.normal * shape1->Radius();
return true;
}
else
{
// Otherwise, find side we're closest to & use that
float dists[] =
{
localToCircle.x - (-halfWidths.x),
halfWidths.x - localToCircle.x,
localToCircle.y - (-halfWidths.y),
halfWidths.y - localToCircle.y
};
int iMin = 0;
for (int i = 1; i < _countof(dists); ++i)
{
if (dists[i] < dists[iMin])
{
iMin = i;
}
}
contact.distance = -(dists[iMin] + shape1->Radius());
switch (iMin)
{
case 0: contact.normal = Vector2(-1, 0); break;
case 1: contact.normal = Vector2(1, 0); break;
case 2: contact.normal = Vector2(0, -1); break;
case 3: contact.normal = Vector2(0, 1); break;
default: assert(false); break;
}
contact.normal = (rotB * contact.normal).Normalized();
contact.worldPosition = body1->Position() - contact.normal * shape1->Radius();
return true;
}
}
Finally, we’ll consider the most complicated of the 3 collision functions we’re discussing, the box/box test. We use a technique called the separating axis test (SAT) for this one. A full explanation of the technique is beyond the scope of this specific post, but there is lots of good info on the web about this. If there is a desire expressed, I can put together a detailed discussion of it in a future blog post. I’ll summarize it as the following for the purpose of this discussion:
The projections of two objects on any axis can be considered, and if there is any separation between the projections along that axis, then the two objects cannot be intersecting.
The key to using this technique is to consider all of the relevant axes (and no more), and early out as soon as a separation is found. If no separation is found after considering the important needed axes, the axis with the least penetration provides the collision info. So, which axes do we test? Well, for 2D this is easy, you test the axes defined by the normals of the faces of each box. We exploit the fact that boxes are parallelograms, so the normals on the left & right side are just inverses for example. So, that’s 2 directions (in world space) per box shape. For finding the projections, we need the min and max points along that axis for each object, and we consider the intervals those min/max pairs form. For this, we’ll briefly introduce a concept called a support mapping. I’ll get into a lot more detail about this later when we discuss other more advanced collision detection methods, but for now I’ll define it simply as a function (defined for a particular shape) that given a direction vector returns the most extreme point (support point) on the shape along that direction.
The algorithm then goes like this: For each of the axes being considered, find the min and max points of each object along that axis. If the intervals don’t overlap, exit the function, there is no collision. While doing this, keep track of the axis with the least overlap. If you get through all axes without a separation condition, use the axis with least overlap to form the contact data for the collision. Here’s the function:
static Vector2 SupportMapping(const BoxShape* box, const Vector2& localDir)
{
Vector2 half = 0.5f * box->Size();
return Vector2(
localDir.x >= 0 ? half.x : -half.x,
localDir.y >= 0 ? half.y : -half.y
);
}
bool CollideBoxBox(RigidBody* body1, RigidBody* body2, ContactInfo& contact)
{
const BoxShape* shape1 = (const BoxShape*)body1->GetShape();
const BoxShape* shape2 = (const BoxShape*)body2->GetShape();
Matrix2 rot1(body1->Rotation());
Matrix2 rot2(body2->Rotation());
Matrix2 invRot1(rot1.Transposed());
Matrix2 invRot2(rot2.Transposed());
Vector2 toBody2 = body2->Position() - body1->Position();
float minPen = FLT_MAX;
Vector2 normal, pointOn1;
Vector2 dirs1[] =
{
rot1.col1,
rot1.col2,
};
float bounds1[] =
{
shape1->Size().x * 0.5f,
shape1->Size().y * 0.5f,
};
for (int i = 0; i < _countof(dirs1); ++i)
{
Vector2 v = dirs1[i].Normalized();
Vector2 pt = toBody2 + rot2 * SupportMapping(shape2, invRot2 * -v);
float d = Dot(pt, v);
float pen = bounds1[i] - d;
if (pen < 0)
{
return false;
}
if (pen < minPen)
{
minPen = pen;
normal = -v;
pointOn1 = pt + normal * pen;
}
// Other way
pt = toBody2 + rot2 * SupportMapping(shape2, invRot2 * v);
d = Dot(pt, -v);
pen = bounds1[i] - d;
if (pen < 0)
{
return false;
}
if (pen < minPen)
{
minPen = pen;
normal = v;
pointOn1 = pt + normal * pen;
}
}
Vector2 dirs2[] =
{
rot2.col1,
rot2.col2,
};
float bounds2[] =
{
shape2->Size().x * 0.5f,
shape2->Size().y * 0.5f,
};
for (int i = 0; i < _countof(dirs2); ++i)
{
Vector2 v = dirs2[i].Normalized();
Vector2 pt = -toBody2 + rot1 * SupportMapping(shape1, invRot1 * -v);
float d = Dot(pt, v);
float pen = bounds2[i] - d;
if (pen < 0)
{
return false;
}
if (pen < minPen)
{
minPen = pen;
normal = v;
pointOn1 = pt + toBody2;
}
// Other way
pt = -toBody2 + rot1 * SupportMapping(shape1, invRot1 * v);
d = Dot(pt, -v);
pen = bounds2[i] - d;
if (pen < 0)
{
return false;
}
if (pen < minPen)
{
minPen = pen;
normal = -v;
pointOn1 = pt + toBody2;
}
}
contact.normal = normal;
contact.distance = -minPen;
contact.worldPosition = body1->Position() + pointOn1;
return true;
}
That wraps up the basics of shapes & collision detection for now. This was a VERY brief overview of the system, so please refer to the code in the repository for more information and to play around with it. We’ll move onto discussing rotations and resolving the actual collisions next!

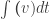


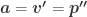
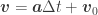
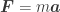


![clip_image002[30]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/2768.clip_5F00_image00230_5F00_77667CF6.gif "clip_image002[30]")
![clip_image002[28]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/3240.clip_5F00_image00228_5F00_50AB53F1.gif "clip_image002[28]")
![clip_image002[26]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/1185.clip_5F00_image00226_5F00_44A963BD.gif "clip_image002[26]")

![clip_image004[6]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/5756.clip_5F00_image0046_5F00_7AF3CF68.gif "clip_image004[6]")
![clip_image008[5]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/4657.clip_5F00_image0085_5F00_25600086.gif "clip_image008[5]")




![clip_image002[12]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/3005.clip_5F00_image00212_5F00_466F6457.gif "clip_image002[12]")
![clip_image004[4]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/6153.clip_5F00_image0044_5F00_5EFF01A7.gif "clip_image004[4]")

![clip_image004[6]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/3581.clip_5F00_image0046_5F00_7E41A87A.gif "clip_image004[6]")
![clip_image006[4]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/5460.clip_5F00_image0064_5F00_4BDDD4FB.gif "clip_image006[4]")



![clip_image002[18]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/4812.clip_5F00_image00218_5F00_4379FFA4.gif "clip_image002[18]")
![clip_image002[20]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/6153.clip_5F00_image00220_5F00_6E5263B6.gif "clip_image002[20]")
![clip_image004[8]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/0361.clip_5F00_image0048_5F00_22F2BFF2.gif "clip_image004[8]")
![clip_image006[6]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/8306.clip_5F00_image0066_5F00_14B44702.gif "clip_image006[6]")
![clip_image002[28]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/6237.clip_5F00_image00228_5F00_4954A33D.gif "clip_image002[28]")
![clip_image004[16]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/3326.clip_5F00_image00416_5F00_3B162A4D.gif "clip_image004[16]")
![clip_image006[14]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/7624.clip_5F00_image00614_5F00_2CD7B15D.gif "clip_image006[14]")
![clip_image002[30]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/7217.clip_5F00_image00230_5F00_338ABAE0.gif "clip_image002[30]")
![clip_image004[18]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/6253.clip_5F00_image00418_5F00_682B171B.gif "clip_image004[18]")
![clip_image008[7]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/5483.clip_5F00_image0087_5F00_47A3D769.gif "clip_image008[7]")
![clip_image010[5]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/7142.clip_5F00_image0105_5F00_39655E79.gif "clip_image010[5]")
![clip_image012[5]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/2450.clip_5F00_image0125_5F00_59143841.gif "clip_image012[5]")
![clip_image004[19]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/3010.clip_5F00_image00419_5F00_3820C59A.gif "clip_image004[19]")
![clip_image002[34]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/1778.clip_5F00_image00234_5F00_05BCF21B.gif "clip_image002[34]")
![clip_image008[9]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/5078.clip_5F00_image0089_5F00_77124635.gif "clip_image008[9]")
![clip_image010[7]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/0285.clip_5F00_image0107_5F00_68D3CD45.gif "clip_image010[7]")
![clip_image014[5]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-45-26-metablogapi/8306.clip_5F00_image0145_5F00_484C8D93.gif "clip_image014[5]")





